잠들어 있는 GPU 성능을 완벽하게 깨우는
AI 인프라 가속의 핵심, AI-Stack
솔루션 개요
대규모 LLM AI 모델 학습과 추론 환경은 GPU 자원의 비효율적 사용, 데이터 I/O 병목 현상, 그리고 복잡한 개발 환경 구축이라는 세 가지 주요 병목에 직면해 있습니다.
INFINITIX AI-Stack은 이러한 문제를 소프트웨어 정의(Software-Defined) 아키텍처로 해결하여 인프라 가치를 극대화하는 AI 전용 운영 플랫폼입니다.
AI-Stack은 LLM학습과 모델 배포까지 AI 개발의 전 과정을 아우르는 끊김 없는 개발 및 서비스 환경을 제공합니다.
개발자에게는 최적의 자동화된 툴셋을, 비즈니스에는 무한히 확장 가능한 개방형 AI 생태계를 선사합니다.
HPC/AI 통합 아키텍처
AI-Stack은 데이터 센터 내의 하드웨어 자원을 논리적으로 통합하여 최적의 경로로 데이터를 처리합니다.
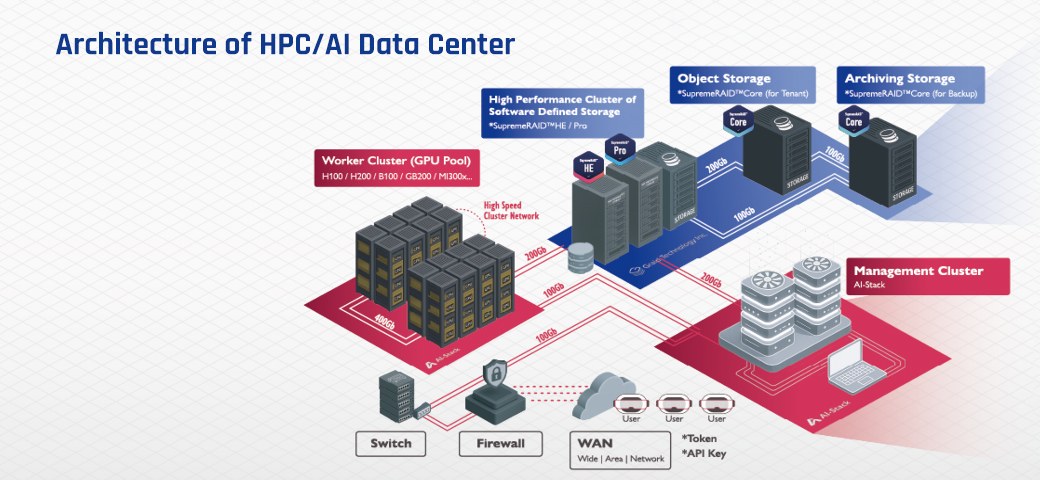
- • Worker Cluster (GPU Pool)NVIDIA 및 AMD 등 최신 GPU가속기 지원
- • Management Cluster (AI-Stack)전체 클러스터의 스케줄링, 리소스 할당, 보안 정책을 제어하는 컨트롤 타워
- • High-Speed Cluster Network200G/400G 패브릭 및 RoCE v2를 통한 초저지연 노드 간 통신
AI Developer EcoSystem Layer
IDE, 학습 네트워크, HPC, 대형 언어 모델, 실험 추적, 워크플로우 오케스트레이션 및 모델 추론 서비스 등 다양한 오픈소스 도구를 아우르며, 효율적인 AI/ML
프로세스를 구축합니다. 개발부터 배포까지 전 과정을 지원하여 데이터 사이언티스트들이 혁신에 집중하고, 성과를 빠르게 실현할 수 있도록 도와줍니다.
-
IDE Tools

-
Experiment Tracking

-
IDE Tools

-
Training Framework

-
HPC

-
Serving Tools

-
Open Source LLMs

AI Developer EcoSystem Layer
GPU 자원 분할 및 다중 테넌트 관리를 제공하여 GPU 활용률을 향상시키고, 사용자 맞춤형 이미지와 배치 작업 스케줄링을 지원하여 AI 개발과 배포 속도를 가속합니다
또한 Kubernetes와의 완벽한 통합을 통해 AI 워크로드 스케줄링을 최적화합니다.
AI-Stack API
- Projects
- Users
- Resources
- Quota
- Authentication & Authorization
AI-Stack Control Plane
- Monitoring Dashboard
- Multi-GPU Computing
- GPU Partitioning
- Multi-Tenant
- Multi-Node
- Custom Image
- Batch Job
- Scheduling
- SSO/LDAP
- CTAs
Workload Orchestration
Infrastructure Cluster Layer
NVIDIA뿐만 아니라 AMD Instinct™ 및 국산 NPU, 글로벌 NPU등 다양한 AI가속기를 지원하며,
NFS, MiniO를 통해 스토리지 아키텍처 지원 및 데이터의 효율적인 흐름을 보장합니다.
AI-Stack Cluster Engine
-

AI Workload
Scheduler -

Storage
permissions -

Container
Orchestration -

GPU
Partitioning
Server Cluster
-
GPU Server Cluster

-
Storage Server Cluster
 NFS, MiniO
NFS, MiniO
AI-Stack 3대 핵심 기술
| 핵심 기술 | 상세 설명 | 기술적 이점 |
|---|---|---|
| GPU Partitioning (분할) |
물리적 GPU 한 장을 여러 개의 독립적인 가상 단위로 분할 |
소규모 학습 및 추론 작업 시 자원 낭비 원천 차단 |
| GPU Aggregation (통합) |
여러 노드에 흩어진 GPU 자원을 하나의 거대한 풀(Pool)로 통합 |
초거대 LLM 모델 학습을 위한 고성능 컴퓨팅 환경 제공 |
| Cross-Node Computing |
노드 간 경계를 허무는 초고속 병렬 컴퓨팅 최적화 |
분산 학습 환경에서 데이터 처리 속도의 선형적 향상 |
핵심 성능 지표 및 기대 효과
| 항목 | 핵심 기능 및 성과 | 비즈니스 가치 |
|---|---|---|
| GPU 자원 활용률 |
GPU Partitioning을 통해 90% 이상 유지 |
유휴 자원을 최소화하여 하드웨어 투자 가치 극대화 |
| 워크로드 실행 속도 |
GPU Aggregation 및 분산 컴퓨팅으로 10배 향상 |
동일 자원 대비 모델 학습 및 서비스 배포 주기 단축 |
| 환경 구축 시간 |
샌드박스 및 DevEnv 구축 1분 이내 완료 |
셋업 시간을 획기적으로 단축하여 엔지니어 생산성 혁신 |
| 경제성 (ROI) | 투자 대비 수익 10배 증대 효과 |
운영 효율성 개선을 통한 인프라 총 소유 비용(TCO) 절감 |
AI-Stack 최대 효율을 위한 2가지 모드
Partitioning

Aggregation

NVIDIA 공인 솔루션 어드바이저
NVIDIA와 파트너십을 맺고 프리미엄 서비스를 제공합니다.
AI-Stack은 전문가용 데이터 센터 컴퓨팅 GPU부터 소비자용 게임 그래픽 카드에 이르기까지
NVIDIA의 모든 GPU 제품 라인을 지원하며 뛰어난 호환성을 제공합니다.
이를 통해 기업은 기존 및 향후 구매할 모든 GPU 리소스를 유연하게 통합하여 하드웨어
투자 수익을 극대화할 수 있습니다.